
Apple
i-4">Как он используется?тся довольно сложные алгоритмы, цель дифференциальной конфиденциальности довольно проста: убедиться, что люди, чьи данные собираются, имеют такой же уровень конфиденциальности, как если бы данные никогда не записывались. Вы никогда не сможете идентифицировать кого-либо, просто взглянув на набор сохраненной информации о нем.Также читайте: Мне нечего скрывать, так почему я должен заботиться о конфиденциальности?
Как работает дифференцированная конфиденциальность
Поскольку данные о нас собираются с беспрецедентной скоростью, и людям это становится не по душе, идея о том, что ваша конфиденциальность может быть математически доказана, начинает выглядеть довольно хорошо. Такие компании, как Microsoft, Google, Apple, Facebook и Uber, либо внедрили его в той или иной форме, либо изучают свои варианты, но еще до того, как крупные те
Contents
Как работает дифференцированная конфиденциальность
ля таких вещей, как конфиденциальные исследовательские данные, медицинские записи и даже детали. переписи населения США.Он делает это путем добавления шума либо к самим хранимым данным, либо к результатам, которые возвращаются, когда кто-то их запрашивает – искажая отдельные фрагменты данных, но сохраняя общую форму. «Шум» — это, по сути, нерегулярность или необъяснимая изменчивость данных, и цель здесь — вставить шум в отдельные точки данных, сохраняя при этом общие показатели, такие как среднее значение, медиана, мода и стандартное отклонение, близкими к тем местам, где они были раньше.
Простая дифференциальная конфиденциальность
Представим, что вас выбрали для участия в революционном исследовании в области социальных наук. Но вот в чем загвоздка: некоторые вопросы могут оказаться для вас потенциально смущающими, компрометирующими или иным образом неудобными. Скажем так, вы бы предпочли, чтобы никто не видел ваше имя рядом с галочкой в столбце «На самом деле мне понравился последний сезон «Игры престолов»».
К счастью, исследователи анонимизировали исследование. Вместо имен вы получаете случайное число, но даже в этом случае люди смогут использовать ваши ответы и сузить выбор до вас.
Эта проблема на самом деле довольно часто возникает в реальном мире, возможно, наиболее известная, когда исследователи смогли не только идентифицировать пользователей Netflix , но даже когда они узнают о некоторых политических предпочтениях. Но что, если бы мы могли подделать эти данные, а также наш опрос, чтобы никто, читающий результаты, не мог знать наверняка, что сказал каждый человек?
Добавление шума при подбрасывании монеты
Вот метод, который мы можем
Простая дифференциальная конфиденциальность
ь и получить результаты, которые в совокупности выглядели бы так, как если бы все говорили правду: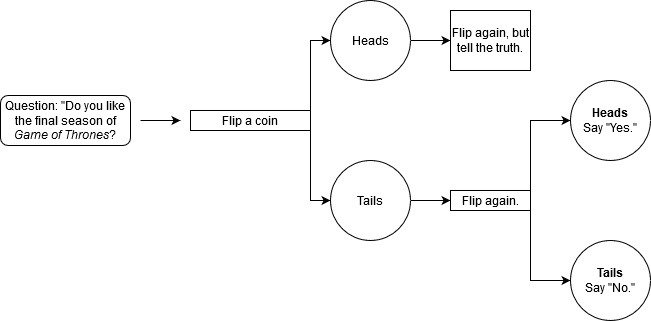
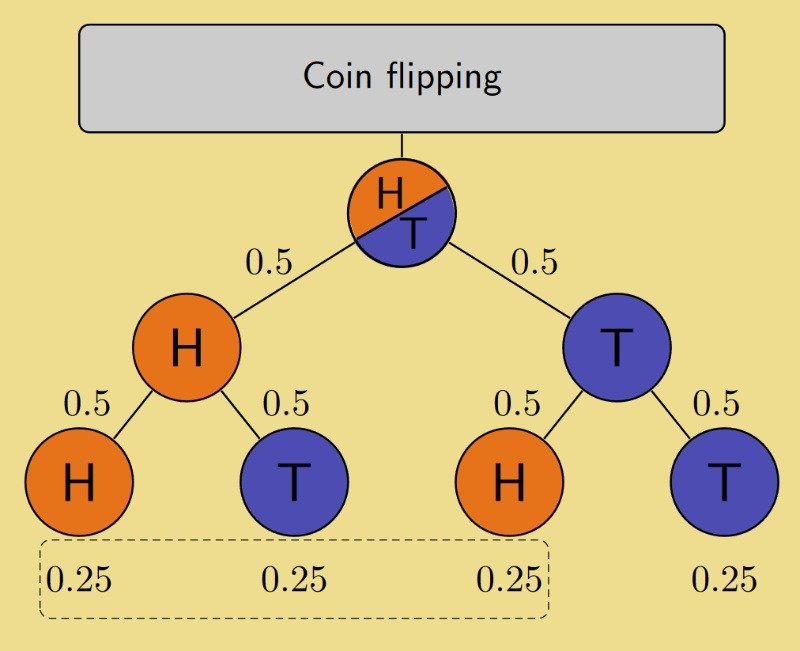
- Мы зададим вам вопрос «да/нет» (вам понравился последний сезон «Игры престолов»?). Вы подбрасываете монетку.
- Если монета выпала орлом, подбросьте ее еще раз. (Неважно, что вы получите во второй раз.) Ответьте на вопрос честно. («Да»).
- Если выпала решка, подбросьте монету еще раз. Если это орел, скажите «Да». Если решка, скажите «Нет».
Мы не будем смотреть на монету, поэтому не узнаем, подсказала ли она вам солгать. Все, что мы знаем, это то, что у вас была 50 % вероятность сказать правду и 50 % вероятность сказать «Да» или «Нет».
Ваш ответ затем записывается рядом с вашим именем или идентификационным номером, но теперь у вас есть правдоподобное отрицание. Если кто-то обвиняет вас в том, что вы получили удовольствие от последнего сезона «Игры престолов», у вас есть защита, основанная на законах вероятности: подбрасывание монеты заставило вас сказать это.
Реальные алгоритмы, которые большинство технологических компаний используют для дифференциальной конфиденциальности, намного сложнее, чем этот (два примера ниже), но принцип тот же. Делая неясным, действительно ли каждый ответ действителен, или даже меняя ответы случайным образом, эти алгоритмы могут гарантировать, что независимо от того, сколько запросов кто-то отправляет в базу данных, они не смогут никого конкретно идентифицировать.
Однако не все базы данных относятся к этому одинаково. Некоторые применяют алгоритмы только при запросе данных, то есть сами данные все еще где-то хранятся в исходной форме. Очевидно, что это не идеальный сценарий конфиденциальности, но применение дифференциальной конфиденциальности в любой момент лучше, чем просто публиковать необработанные данные в мире.
Как он используется?Добавление шума при подбрасывании монеты
https://saintist.ru/wp-content/uploads/2024/05/differential-privacy-apple-hademard-mean-count-sketch.jpg" alt="Дифференциальная конфиденциальность Эскиз среднего подсчета Apple Хадемара">Apple использует дифференциальную конфиденциальность для маскировки отдельных пользовательских данных до того, как они будут им отправлены, используя логику, согласно которой, если много людей отправляют свои данные, шум не окажет существенного влияния на совокупные данные. Они используют технику под названием «Подсчет среднего эскиза», которая, по сути, означает, что информация кодируется, случайные фрагменты изменяются, а затем «неточная» версия декодируется и отправляется в Apple для анализа. Он сообщает о таких вещах, как предложения по вводу, подсказки по поиску и даже смайлики, которые появляются, когда вы вводите слово.
Читайте также: Apple добавляет конфиденциальность с помощью «Войти с помощью Apple», но будут ли этому доверять пользователи?
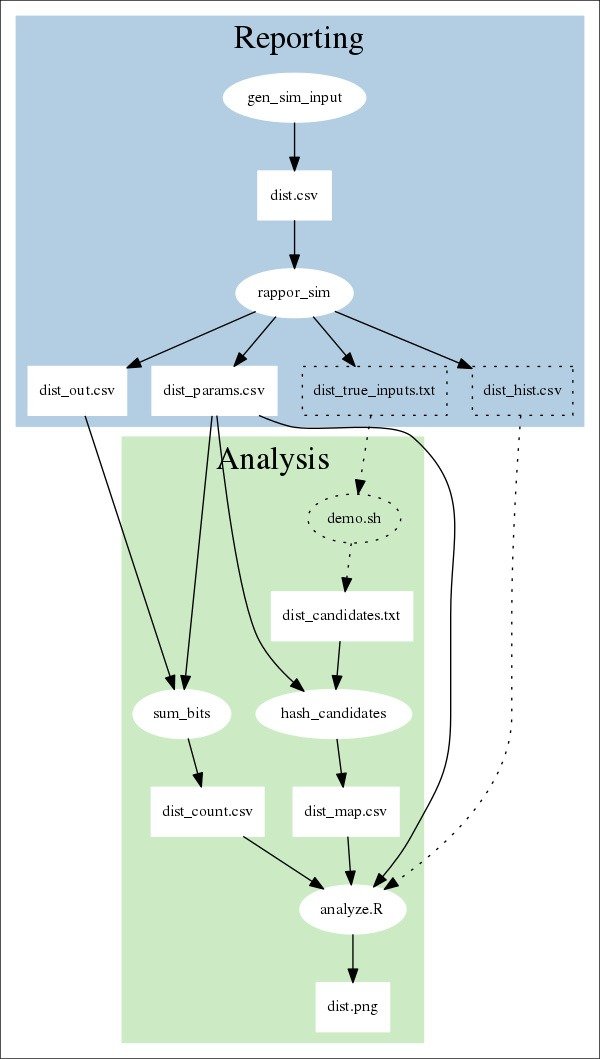
Первым крупным набегом Google на дифференциальную конфиденциальность стала программа RAPPOR (рандомизированный агрегированный порядковый ответ с сохранением конфиденциальности) , которая пропускает данные через фильтр и случайным образом меняет их фрагменты, используя версию метода подбрасывания монеты, описанную выше. Первоначально они использовали его для сбора данных о проблемах безопасности в браузере Chrome, а с тех пор стали применять дифференциальную конфиденциальность в других местах, например, для определения загруженности бизнеса в любой момент времени без раскрытия активности отдельных пользователей. На самом деле они открыли исходный код этого проекта, поэтому на основе их работы могут появиться новые приложения.
Почему не все данные обрабатываются таким образом?
Дифференциальную конфиденциальность в настоящее время сложно реализовать, и она требует компромисса в точности, что в некоторых случаях может негативно повлиять на критически важные данные. Алгоритм машинного обучения, использующий приватизированные данные для конфиденциальных медицинских исследований, может, например, совершать ошибки, достаточно серьезные, чтобы убить людей. Тем не менее, он уже находит реальное применение в мире технологий, и, учитывая растущую осведомленность общественности о конфиденциальность данных , есть большая вероятность, что в будущем мы увидим математически доказуемую конфиденциальность, рекламируемую как аргумент в пользу продажи.
Авторы изображений: Поток данных РАППОР , Серверный алгоритм для эскиза среднего подсчета по Хадемару , Пакет Dataset-опросов R-MASS , Дерево вероятностей – подбрасывание монетки