
Средняя фотография, вероятно, стоит значительно меньше тысячи слов — из селфи можно многому научиться. Но иногда вам просто нужно знать, откуда взялось изображение, независимо от того, сколько слов оно стоит.
Для этого есть поисковые системы обратного изображения от таких компаний, как Google, TinEye, Bing, Yandex, Pixsy и многих других. Однако, поскольку вы не указываете никаких слов в своем запросе, откуда они узнают, что искать? И, самое главное, как они его находят? Принципы работы обратного поиска изображений в каждой поисковой системе различаются, и они держат свои точные алгоритмы в тайне, но основные идеи уже известны, и их не так сложно понять.
Читайте также: 7 лучших поисковых систем для обеспечения конфиденциальности
Отпечатки пальцев
Фотографии на самом деле могут быть более уникальными, чем отпечатки пальцев человека, поскольку вероятность того, что две фотографии будут содержать одно и то же расположение пикселей, невообразимо бесконечно мала, а вероятность столкновения отпечатков пальцев составляет около 64 миллиардов — сравнительно хороший шанс. Но как снять отпечаток пальца с фотографии? Шаги различаются в зависимости от алгоритма, но большинство из них следуют одной и той же базовой формуле.
Во-первых, вам необходимо измерить характеристики изображения, которые могут включать цвет, текстуры, градиенты, формы, взаимосвязи между различными частями
Contents
Отпечатки пальцев
вещи, как преобразование Фурье (метод разложения изображений на синус и косинус)..Предположим, мы ищем следующее изображение и нам нужен его отпечаток.

Для этого мы можем, среди прочего, использовать цветовую гистограмму изображения, преобразование Фурье и карту текстур, каждую из которых вы можете увидеть ниже.
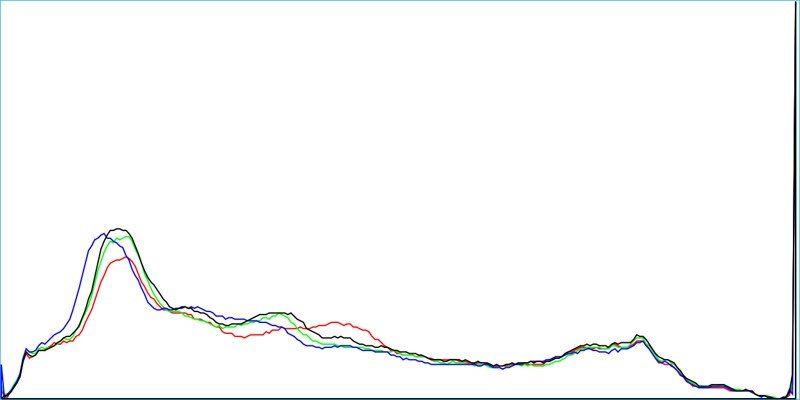


Если изображение было изменено, размыто, повернуто или иным образом изменено, для поиска совпадений будет использоваться ряд алгоритмов, использующих описанные выше и другие функции.
Кодирование, хранение и поиск
Каждая функция изображения в отпечатке пальца может быть закодирована в виде строк букв и цифр, которые легко хранить и индексировать в базе данных. Какая бы комбинация функций ни была извлечена и сохранена, она станет записью поисковой системы обратного изображения для этого изображения. Например, по состоянию на февраль 2020 года база данных TinEye содержит около 39,6 миллиарда проиндексированных изображений. Это означает, что они запустили свой алгоритм для такого количества изображений и сохраняют все эти отпечатки пальцев для сравнения с найденными изображениями.

Вторая важная часть алгоритма — определение похожих изображений. Когда вы загружаете изображение, оно проходит через алгоритм снятия отпечатков пальцев поисковой системы по обратным изображениям. Затем поисковая система попытается найти записи с наиболее близкими отпечатками пальцев, называемыми «расстоянием изображения». Решение о том, какие факторы сравнивать и как их взвешивать, также принимает каждая поисковая система, но в основном они стремятся найти общее расстояние до изображения как можно ближе к нулю.
А как насчет машинного обучения/ИИ?
Благодаря описанным выше методам снятия отпечатков пальцев и индексации обратный поиск изображений был довольно хорош еще до того, как к нему стало практично применять ИИ. Однако, поскольку ИИ превосходно обрабатывает изображения, такие вещи, как сверточные нейронные сети (CNN), скорее всего, используются многими крупными поисковыми системами для извлечения и маркировки функций. Google, например, мог бы использовать CNN в обратном поиске изображений, что позволит ему подобрать вероятные ключевые слова для изображения и выдать релевантные результ
Кодирование, хранение и поиск
и уже довольно давно делают в Google Photos.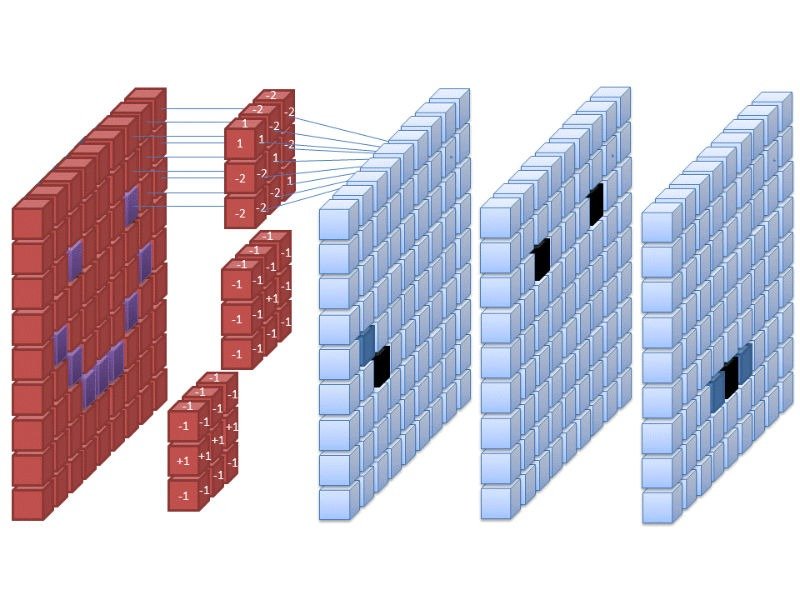
Это ставит обратный поиск изображений на шаг выше простого извлечения признаков и определения расстояния до изображения. Сверточные нейронные сети по сути пропускают изображения через несколько фильтров, которые отображают несколько различных типов функций, а затем пытаются их классифицировать на основе предыдущего обучения. Конечно, это чрезмерное упрощение, но достаточно сказать, что CNN делают поиск изображений гораздо более точным и полезным и, вероятно, реализуются наряду со старыми методами снятия отпечатков пальцев компьютерного зрения.
Какая поисковая система по обратным изображениям лучшая?
Различные алгоритмы означают, что разные поисковые системы изображений хороши в разных задачах, хотя в конечном итоге все они преследуют одну и ту же цель: найти совпадение с загруженным вами изображением. Например, Google изображения имеет довольно хороший процент попаданий, но делает много «наилучших предположений», что дает вам много похожих, но не идентичных фотографий. Это здорово, если вас интересует настроение или общая категория, но такой механизм, как TinEye , гораздо больше ориентирован на поиск идентичных изображений, даже если они сильно отредактированы, и может даже идентифицировать изображения внутри фотографий. что делает его немного лучше, если вам нужно точное совпадение.
Российская поисковая система Яндекс также имеет репутацию превосходного инструмента для поиска изображений, хотя, возможно,
А как насчет машинного обучения/ИИ?
ся с русской тематикой. Такие инструменты, как Pixsy и ImageRaider, ориентированы на выявление случаев несанкционированного использования, поэтому они, как правило, включают в себя больше функций, таких как оповещения, и сосредоточены на мониторинге пользовательских библиотек фотографий.Поскольку алгоритмы постоянно меняются и, как правило, остаются заблокированными, стоит проверить несколько разных систем, если одна из них не возвращает нужные результаты.
Авторы изображения: Пар с улицы Нью-Йорка , DB-database-icon