
Каждый пользователь Linux наверняка знает, что grep — это надежный инструмент командной строки для углубленного поиска файлов. Тем не менее, многие новички избегают его, потому что им не нравится терминал. Приложения, представленные в этой статье, не совсем альтернативы grep , потому что в некоторых сценариях использования grep действительно незаменим. Вместо этого давайте назовем их визуальными обновлениями grep, потому что они расширяют функциональность grep и обертывают ее в полноценный графический интерфейс.
1. Регулярное выражение
Регекссер — это практичный инструмент поиска файлов, который позволяет редактировать файлы прямо из его интерфейса. Вы можете искать файлы и папки по имени и просматривать текстовые файлы (включая файлы HTML и XML). В левой части окна вы можете выбрать целевую папку и шаблон (по
Contents
1. Регулярное выражение
txt только для текстовых файлов). Regexxer может выполнять рекурсивный поиск во вложенных папках любой выбранной папки и включать в результаты скрытые файлы.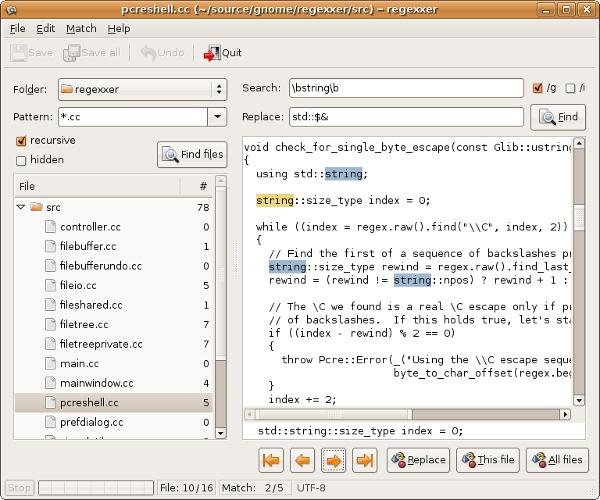
Правая часть окна позволяет выполнить «поиск и замену» выбранного файла. Здесь вы можете заменить только один экземпляр найденной фразы или все автоматически. Вы также можете заменить выбранную фразу во всех найденных файлах, что удобно при пакетном редактировании.
2. Поисковая обезьяна
Раньше Поискмонки был очень популярен. В какой-то момент разработка версии для Linux прекратилась, и теперь сайт предлагает новые загрузки только для Windows. Тем не менее, старую версию можно установить из репозиториев почти каждого дистрибутива Linux. Возможно, это удивительно, но он отлично работает и очень быстро. Вы можете использовать Searchmonkey для поиска найти файлы и папки по имени или просматривать их содержимое и искать фразы с помощью регулярных выражений.
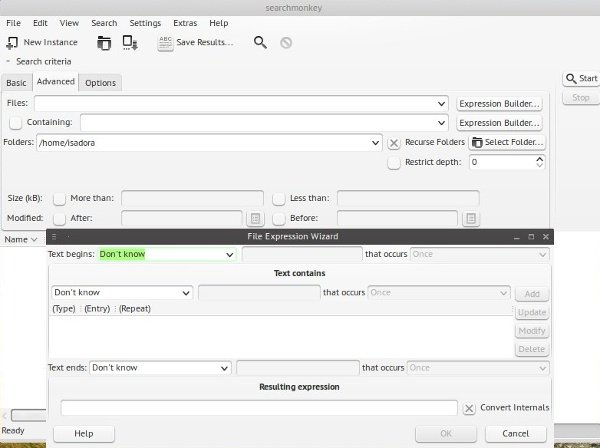
Searchmonkey помогает создавать сложные запросы с помощью мастера выражений файлов (активируется нажатием кнопки «Построитель выражений») и параметра «Проверить регулярное выражение» (в меню «Дополнительно»). Он может искат
2. Поисковая обезьяна
е установить глубину поиска (сколько подпапок он должен просматривать) и фильтровать файлы по размеру и дате. На вкладке «Параметры» вы можете ограничить количество файлов в результатах и выбрать, сколько строк контекста вы хотите видеть.3. Сборщик документов
Вместо прямого поиска в вашей файловой системе Сборщик документов предложит вам создать индекс, а затем искать ваши запросы только в индексированных файлах. Он предлагает портативную версию (просто распакуйте ее и запустите файл.sh с терминала) как для 32-, так и для 64-битных систем. Чтобы создать индекс, щелкните правой кнопкой мыши область «Область поиска» слева.
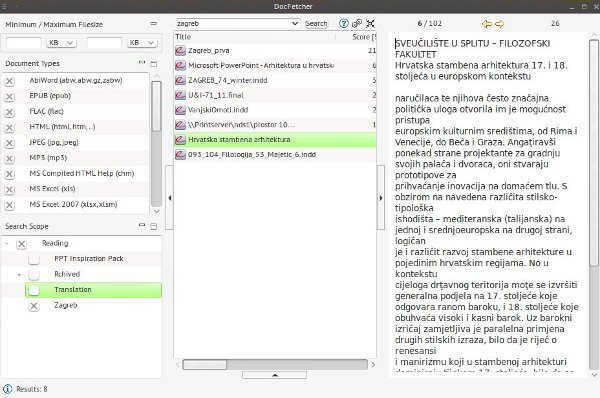
Вы можете добавлять папки в индекс, приостанавливать создание индекса и продолжить его позже, индексировать архивные файлы (ZIP, TAR) как папки, а также исключать выбранные файлы из индекса с помощью обычные выражения .
DocFetcher имеет встроенный механизм обработки HTML, который позволяет просматривать файлы HTML с форматированием и изображениями. Он предлагает возможность удаления истории поиска с учетом конфиденциальности и позволяет выполнять поиск в файлах и внутри файлов с использованием подстановочных знаков, логических операторов, нечеткого поиска (находит похожие слова), поиска по близости (на каком расстоянии слова должны находиться друг от друга в тексте) и более. DocFetcher поддерживает впечатляющее количество форматов, включая файлы Microsoft и Libre Office (DOC, DOCX, ODT, OTP…), PDF и EPUB, HTML и XML, файлы электронной почты Outlook PST, а также метаданные аудио и изображений.
4. Вернуть
вернуть — поисковая система для вашего компьютера; что-то вроде Google, но для ваших файлов и папок.
3. Сборщик документов
аботает в Linux, OS X и Windows при условии, что у вас правильно установлена и настроена Java. Установочный файл доступен на сайте проекта , и вы можете просто извлечь его в папку, открыть эту папку в терминале и запуститьjava -jar regain.jar, чтобы запустить приложение. (Файл «regain.jar» должен быть исполняемым). Regain будет работать в вашем веб-браузере по умолчанию.
Чтобы найти ваши файлы и папки, Regain сначала должна просканировать вашу систему и создать поисковый индекс. В форме «Настройки» вы добавляете папки, которые хотите проиндексировать. Если вы не хотите включать в индекс определенные файлы, занесите их в черный список в файле «CrawlerConfiguration.xml». Как только вы начнете использовать Regain, он будет выполнять поиск по индексу вместо сканирования всего жесткого диска. Это экономит системные ресурсы и ускоряет поиск.
5. PDFgrep
Из всех инструментов в этом списке PDFgrep больше всего похож на оригинальный grep, но он также «необычный», поскольку это инструмент командной строки. Некоторые дистрибутивысодержат PDFgrep в своих репозиториях, но необходимо скомпилировать самую новую версию (сейчас 1.3.2).
Хотя grep выводит номер строки, в которой появляется строка поиска, PDFgrep вместо этого покажет вам номер страницы, что более полезно для файлов PDF, поскольку мы склонны читать их как книги, а не анализировать их построчно. PDFgrep работает только с файлами PDF. Их необходимо либо преобразовать из текста, либо распознать с помощью оптического распознавания символов, а не просто отсканировать изображения.
Чтобы найти слово в файле PDF, введите:
pdfgrep word filename.pdf
Чтобы игнорировать регистр, используйте параметр -i:
pdfgrep -i word filename.pdf
Это позволит найти «Слово», «слово», «СЛОВО» и другие возможные комбинации. Если вы ищете фразу, заключите ее в кавычки. Вот некоторые полезные опции:
-n: выводит номер страницы для каждого совпадения.-c: печатается только количество совпадений в4. Вернуть
de>-pпоказывает количество совпадений на странице.-C NUMBER: печатает выбранное количество символов вокруг каждого совпадения с контекстом. Вместо числа вы можете написать «строка», и PDFgrep напечатает всю строку.
PDFgrep может рекурсивно искать во всех подпапках активной папки и просматривать несколько файлов PDF. Он также поддерживает обычные выражения , параметры можно комбинировать:
pdfgrep -nH "Linux world" file1.pdf file2.pdf /home/user/Desktop/newfile.pdf
При этом будет напечатан номер страницы и имя файла для каждого совпадения (из-за опции -H).
Какие инструменты и команды Linux вы используете для поиска файлов? Поделитесь своими любимыми в комментариях ниже.