![]() После grep следующим логическим шагом будет обучение по sed. Команда sed поступает из Stream EDitor и, как следует из названия, она имеет дело с текстовым потоком. Однако, хотя sed — одна из самых мощных команд в Unix, ее справочная страница также является одной из самых загадочных. В этой статье я попытаюсь обобщить основные принципы использования sed, а затем приведу несколько примеров расширенных сценариев.
После grep следующим логическим шагом будет обучение по sed. Команда sed поступает из Stream EDitor и, как следует из названия, она имеет дело с текстовым потоком. Однако, хотя sed — одна из самых мощных команд в Unix, ее справочная страница также является одной из самых загадочных. В этой статье я попытаюсь обобщить основные принципы использования sed, а затем приведу несколько примеров расширенных сценариев.
Основы
Общая команда для sed выглядит примерно так:
sed [option] '{script}' [text file]
Sed выполнит необходимые вам операции с текстовым файлом и отобразит результат в стандартном выводе. Если вам нужен результат в текстовом файле, вы можете перенаправить его обычным способом:
sed [option] '{script}' [text file] > [edited text file]
Или используйте опцию «-i», которая позволит напрямую редактировать входной файл:
sed -i[option] '{script}' [text file]
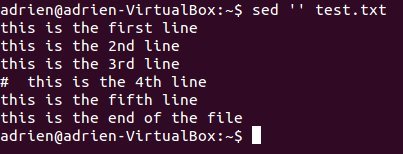
Теперь приступим к работе над сценарием. Самый очевидный первый шаг — это нулевой скрипт:
sed '' test.txt
просто отобразит текст в test.txt.
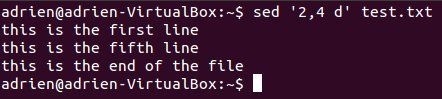
Хорошее использование sed — удаление. Давайте потренируемся на примерах.
sed '2,4 d' test.txt
удалит строки со 2 по 4 из test.txt.
Вы можете догадаться, что синтаксис скрипта:
sed '[first line to delete] [last line to delete] d' test.txt
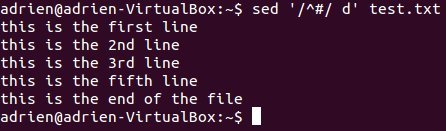
Но самое интересное возникает, когда вы используете регулярные выражения или регулярные выражения в качестве разделителя для удаления. Например,
sed '/^#/ d' test.txt
удалит каждую строку, начинающуюся с «#» (другими словами, если вы кодируете, будут удалены все ваши комментарии).
Общий синтаксис:
sed '/regex/ d' test.txt
для удаления строки, содержащей регулярное выражение.
sed '/regex1/,/regex2/ d' test.txt
для удаления интервала от строки, содержащей регулярное выражение1, до строки, содержащей регулярное выражение2.
Специальный символ «^», который я использовал в первом примере, предназначен для обозначения начала строки.
Тогда второе основное использование, которое я могу придумать, — это замена. Общий синтаксис:
sed -re 's/regex1/regex2/' test.txt
Действует эффект поиска в первой строке регулярного выражения 1, замены его на регулярное выражение 2, перехода к следующей строке и повторения до конца потока ввода.
Хороший пример:
sed -re 's/^# *//' test.txt
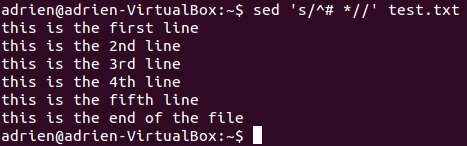
Он заменит символ «#» в начале строки, а все пробелы ничем. Другими словами, он раскомментирует текстовый файл. Символ «*» — это метасимвол, обозначающий здесь 0 или более пробелов.
Дополнительно
С помощью sed можно делать довольно причудливые вещи, но вы довольно быстро достигнете предела, если не обратите внимания на его базовое поведение. Sed работает с потоком линейно: он применяет построчную обработку к текстовому файлу. Если вы хотите внести более одного изменения в одну и ту же строку, вам придется использовать метки и многострочную обработку. Все это может стать очень сложным и очень быстро. Сейчас я покажу вам несколько продвинутых примеров и объясню их. Если вам нужно больше, я уверен, что вы можете выполнить поиск самостоятельно и использовать основы, которые я вам дал.
Если вы хотите удалить пустые строки файла, вы можете использовать команду
sed -re '/^$/ {N; D}' test.txt
Метасимвол «$» означает конец строки, поэтому «^$» обозначает пустую строку. Тогда «{N;D}» — это довольно сложный синтаксис для указания удалить эту строку.
Если вы хотите удалить все теги в html-файле, эта команда для вас:
sed -re ':start s/]*>//g; / {N; b start}' test.txt
Символ «:start» называется меткой. Это немного похоже на тег внутри скрипта, к которому мы хотим вернуться позже, чтобы применить несколько изменений к одной и той же строке. sed ищет что-либо в форме «
Заключение
Теперь вы готовы более глубоко изучить sed или просто использовать его для простых модификаций. Эту команду я считаю особенно полезной в сценариях в целом, но мне потребовалось некоторое время, чтобы понять ее синтаксис. Надеюсь, у вас это будет намного быстрее.
Знаете ли вы еще одну базовую команду для sed? Или вы используете другой расширенный сценарий, включающий sed, которым хотите поделиться? Пожалуйста, дайте нам знать в комментариях.